
로딩 중이에요... 🐣
20 인덱스 열 이름 변경 | ✅ 저자: 이유정(박사)
1. 열(Column) 이름 바꾸기
df.rename(columns={'customer_id': '커스터머ID', 'age': '나이'}, inplace=True)
rename(columns={...})은 특정 열 이름만 선택적으로 변경할 때 사용합니다.
- 예:
customer_id→커스터머ID,age→나이 inplace=True는 원본 df를 직접 바꾼다는 뜻
2. 열 이름 일괄 변경하기
df.columns = ['커스터머ID', '이름', '나이', '이메일', '가입일시']
이 방법은 모든 열 이름을 한꺼번에 바꿀 때 사용합니다.
단, 열 개수와 바꿀 이름 개수는 일치해야 해요!
3. 인덱스(Index) 이름 바꾸기 (지정된 일부만)
df.rename(index={0: '첫번째', 1: '두번째', 2: '세번째'}, inplace=True)
index={...}는 행 번호(인덱스)를 지정해서 이름을 바꿔요.
- 원래 0번째 행 → '첫번째'
- 1번째 행 → '두번째' 이건 일부 행만 바꾸고 싶을 때 유용해요.
4. 인덱스 전체를 규칙적으로 변경하기
def index_gen(num):
return '커스터머_' + str(num)
df.index = df.index.map(index_gen)
df.index.map()은 전체 인덱스를 하나씩 바꿀 때 사용해요.
- 예: 0 → "커스터머_0", 1 → "커스터머_1", 2 → "커스터머_2" … 이건 규칙적으로 행 번호에 접두어 붙이고 싶을 때 아주 편리합니다.
실습하기:
[선택한 열 이름 바꾸기 - rename() 사용]
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
df.rename(columns={'customer_id': '커스터머ID', 'age': '나이'}, inplace=True)
print(df)
특정 열 이름만 바꾸고 싶을 때 사용하는 방법
[전체 열 이름 한꺼번에 바꾸기 - df.columns 대입]
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
df.columns = ['커스터머ID', '이름', '나이', '이메일', '가입일시']
print(df)
열 이름을 한 줄로 전부 새로 지정하는 방식 순서대로 이름을 넣어주면 기존 열 이름이 이걸로 전부 바뀝니다. 주의: 열(column)의 개수와 새로운 이름의 개수가 반드시 같아야 해요!
[일부 인덱스 이름 바꾸기 - rename(index=...) 사용]
import pandas as pd
# CSV 파일 불러오기
df = pd.read_csv("csv_files/combined_customers.csv")
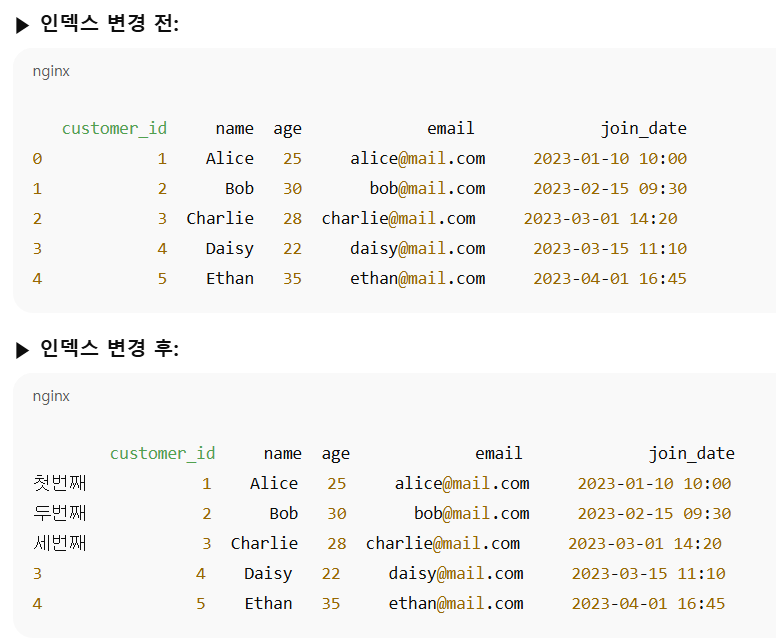
# 인덱스 변경 전 상위 5행 출력
print("▶ 인덱스 변경 전:")
print(df.head())
# 일부 인덱스 이름 변경
df.rename(index={0: '첫번째', 1: '두번째', 2: '세번째'}, inplace=True)
# 인덱스 변경 후 상위 5행 출력
print("\n▶ 인덱스 변경 후:")
print(df.head())
행의 번호(= 인덱스)를 일부만 직접 이름으로 바꿀 때 쓰는 방법
- 0번째 행 → '첫번째'
- 1번째 행 → '두번째'
- 2번째 행 → '세번째'
나머지 인덱스는 그대로 숫자로 남아 있어요.
index를 변경하는 이유는 단순히 보기 좋게 하기 위한 것 외에도, 실제 분석·검색·출력 시 효율적이고 의미 있게 활용하기 위해서입니다.
Pandas에서 인덱스는 각 행(row)을 식별하는 고유한 라벨이에요.
엑셀로 치면 왼쪽 가장 첫 번째 열(A열 앞에 있는 번호 줄)이 인덱스입니다.
✅ 인덱스를 바꾸는 이유:
1. 가독성 향상(사람이 보기 쉽게)
2. 데이터 검색/필터링을 더 직관적으로 하기 위해
- df.loc["커스터머_3"] # 3번 고객 정보 바로 찾기
3. 데이터를 그룹으로 묶을 때
4. 예를 들어 고객을 이메일 도메인별로 그룹짓고 싶을 때:
df.set_index("email_domain", inplace=True)
이런 식으로 의미 있는 열을 인덱스로 바꿔 놓으면, 그룹별 분석이나 집계할 때 아주 유용해요.
상황예시: 고객 이메일 도메인별로 나누고 싶다
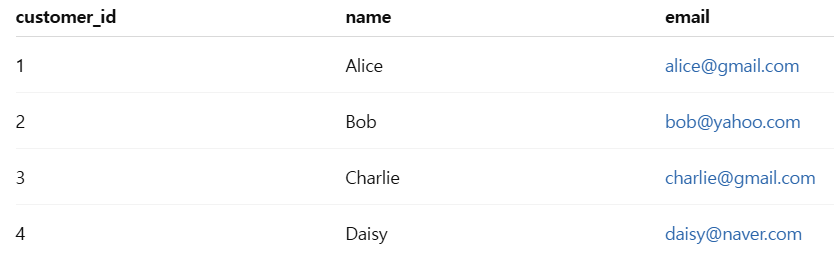
1단계: 이메일 도메인 추출
df['email_domain'] = df['email'].str.split('@').str[1]
이메일에서 @ 뒷부분만 뽑아 email_domain이라는 새 열을 만듭니다.
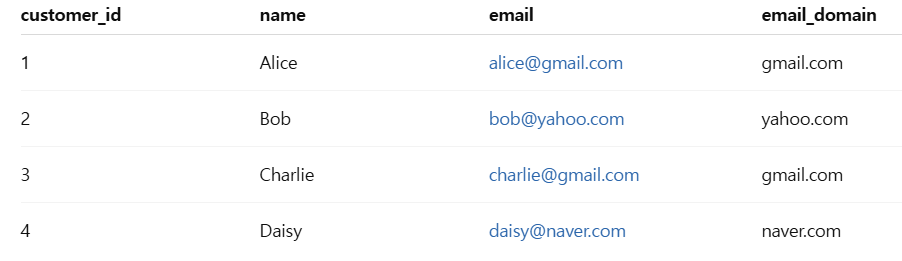
2단계: 의미 있는 열을 인덱스로 바꾸기
df.set_index("email_domain", inplace=True)
원래 0, 1, 2 이런 숫자 인덱스를 이메일 도메인으로 바꿔서 행을 구분해요.
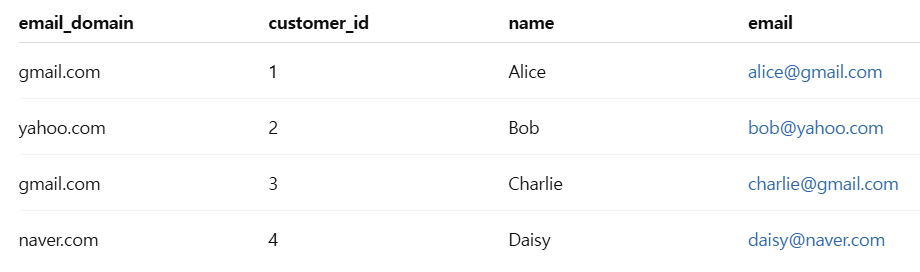
3단계: 그룹 분석에 활용 (groupby)
이제 인덱스를 gmail.com, yahoo.com, naver.com 같은 값으로 바꿨으니, 같은 도메인끼리 묶어서 분석할 수 있어요.
df.groupby(df.index).count()

gmail.com 도메인을 가진 고객이 2명이라는 걸 쉽게 알 수 있죠!
5. 시간 순 정렬/인덱싱
시간 기반 데이터에서는 보통 날짜나 시간을 인덱스로 설정해요:
df.set_index("join_date", inplace=True)
df.loc["2023-01-01":"2023-01-31"] # 1월 가입자만 추출
기간 필터링, 이동 평균 계산, 리샘플링 등 시계열 분석에 꼭 필요해요.
6. 중복 방지 및 고유 식별자 활용
df.set_index("customer_id", inplace=True)
고객 ID처럼 고유한 값을 인덱스로 설정하면, 중복 없이 관리하고 특정 행을 빠르게 찾을 수 있어요.
[인덱스를 규칙적으로 바꾸기 - map() 사용]
import pandas as pd
def index_gen(num):
return '커스터머_' + str(num)
df = pd.read_csv("csv_files/combined_customers.csv")
df.index = df.index.map(index_gen)
print(df)
모든 행의 인덱스를 커스터머_0, 커스터머_1, 커스터머_2, … 이런 식으로 규칙적으로 바꾸는 방법
map() 함수는 각 인덱스 번호에 대해 index_gen() 함수를 적용해서 새로운 이름으로 만들어줘요.
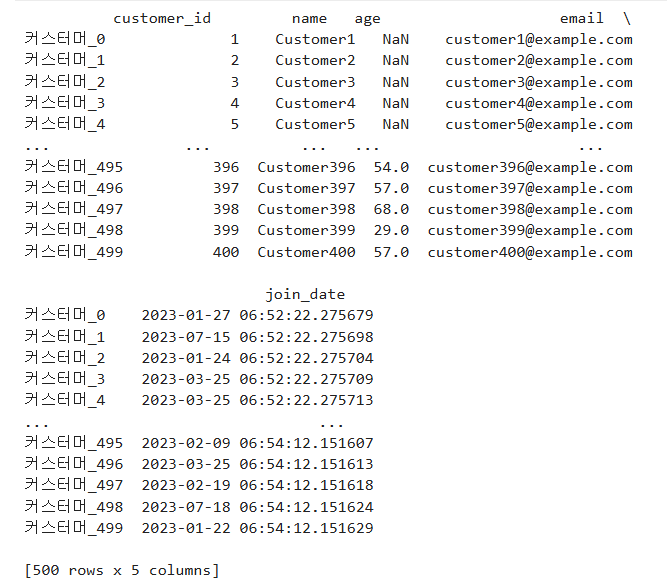
실습 문제 인덱스 및 열 이름 변경하기 목표:
- 고객 데이터를 불러와서 보기 좋고 분석하기 쉽게 가공합니다.
- 불필요한 인덱스를 제거하고, 열 이름을 직관적인 한글로 바꿔 사용자가 이해하기 쉬운 표를 완성합니다.
[문제 배경]
마케팅 분석팀의 데이터 담당자로써,
팀원들이 이 데이터를 엑셀로 받아 보고서에 붙이는데, 열 이름이 영어고 인덱스도 의미가 없어 보기 불편하다고 합니다.
요구사항:
customer_id컬럼은 고객 식별자이므로, 이를 행 인덱스로 사용하고 싶습니다.- 나머지 열들의 이름을 모두 한글로 변경해 주세요.
reset_index()없이customer_id가 진짜 인덱스가 되도록 설정합니다.- 바뀐 결과를
head()로 상위 5개 행만 출력해 확인해 주세요.
요구 출력 결과 (예시) 여기서 "커스터머ID"는 인덱스입니다.
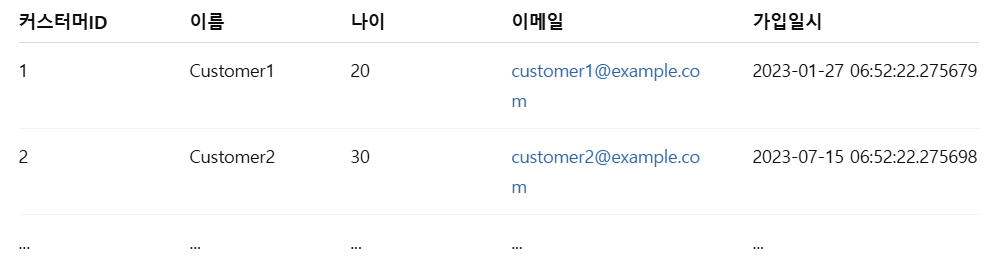
작성해야 할 작업 순서
csv_files/combined_customers.csv파일을df로 읽어옵니다.customer_id를 행 인덱스로 설정합니다.- 열 이름을 다음과 같이 변경합니다:
name→이름age→나이email→이메일join_date→가입일시
- 최종 결과에서 상위 5개 행을 출력합니다.
정답코드
import pandas as pd
# 1. CSV 파일 읽기
df = pd.read_csv("csv_files/combined_customers.csv")
# 2. customer_id를 인덱스로 설정
df.set_index("customer_id", inplace=True)
# 3. 열 이름 변경
df.rename(columns={
"name": "이름",
"age": "나이",
"email": "이메일",
"join_date": "가입일시"
}, inplace=True)
# 4. 결과 확인
print(df.head())